After watching Richard Feldmans presentation about Rust and Elm, it is obvious that language choices are about trade-offs. The presentation does a good job explaining the benefits and trade-offs with each language – especially compared to more conventional languages such as JavaScript and C++.
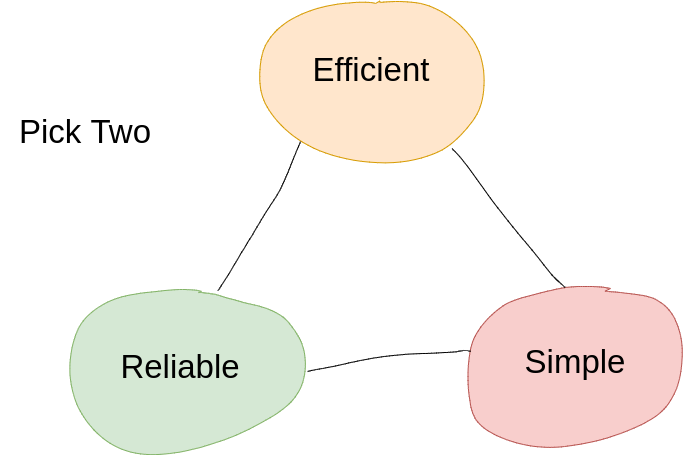
As in many aspects of life, you can’t have everything – you need to optimize for something. One way to look at programming languages is what I’ll call the “programming triangle.” Similar to the project management triangle – the programming triangle is: Fast, Reliable, Simple – pick two – you can’t have all three.
- Efficient: speed and size
- Simple: language complexity, tooling, deployment, etc.
- Reliable: low run time exceptions, secure, easily decipherable stack traces, etc.
There is also the issue of optimizing for domains. Rust is fast when running on a native machine, but much slower and larger than Elm in the frontend. Thus it often makes sense to use different languages depending on the domain you are working in. Sometimes the domain dictates the language – such as embedded microcontroller programming where often C/C++ is the only practical option. Some languages optimize one attribute aggressively at the expense of the other two. One example is Python – it is very simple to use, but compared to other options is relatively unreliable and inefficient. However, when working on one-off data science problems, simplicity and ease of use is most important – especially when paired with fast libraries. There is a huge difference between writing a program written by one person to solve one problem on one computer at one point in time (examples: data science calculations, excel macros, and university class assignments), and writing a program that will be developed by a team, deployed on many systems, and maintained over an extended period of time. In the first case (what I call one-off programs), it really does matter what you use. However, if we want a program to scale with developers, deployments, features, and time, then we need to think seriously about the programming triangle – what is important for project success.
For programs that need to scale, we should be wary of languages that don’t do any, or only one of these attributes well, such as Javascript on the backend. C++ is another example – it is neither reliable or simple, but its momentum keeps it in high use, and sometimes the availability of libraries (such as Qt) make it a good choice.
Having used Elm for 1.5 years now, I concur with Richard – it is a delightful language and I don’t worry about run time errors any more. I’m still using Go for most cloud and embedded Linux applications, and it meets my needs very well. I’ve also found Go to be a very reliable language. It has garbage collection, which eliminates most memory errors/bugs. It has types which catch a host of problems at compile time. And Go’s idioms tend toward writing simple, reliable code. With both Elm and Go, I’m optimizing for reliability and simplicity, which I think is the right choice for projects like Simple IoT. I’ve not used Rust for any projects yet, but likely will at some point when efficiency is important.
I’ve wondered for some time why using Elm and Go in the same project makes sense – it feels right, but it is nice to have a more objective answer. Go is a procedural/imperative language, and Elm is a pure functional language. When we think of a language, we most often think about the programming paradigm – procedural, object oriented, functional etc. Would it not make more sense to write the back-end in Haskell or O’Caml to match the frontend. There is much more to languages than the programming paradigm which is simply the “look” of the language. In the real world, looks are only skin deep – what really matters is how everything maps into the core attributes you value.
