“Code is a liability, not an asset. Aim to have as little of it as possible.”
Whether the open-source code in your projects is an asset or a liability depends on how you handle it. Almost all code in complex systems needs to be maintained.
If you do not update the OSS code in your projects, you are essentially forking it, and it is now “your code” and you own it. It is a static entity that is not gaining value unless you put direct effort into it. Additionally, there will likely be issues that you now need to solve. Very few OSS project maintainers are going to be interested in helping you fix a problem in a 5-year-old snapshot.
Alternatively, if you keep the OSS code in your projects up-to-date, then many issues automatically get fixed (security, compatibility, performance, bugs, new features, etc.). Additionally, if there is a problem, then maintainers will likely work with you to fix it. In this scenario, OSS code is an asset – it is gaining much more value than your direct effort. However, you must commit to:
updating OSS components regularly
having an automated way to comprehensively test the system
engage with the OSS projects you use, build relationships, and contribute where you can (documentation and bug reports are contributions)
Do you need a quick way to track some data? Serial numbers, part numbers, test results, defect metrics, etc.?
There are many ways, but one of the quickest and most flexible options is using CSV files in Gitea. You are already using Git*, right?
With CSV files in Gitea, you can:
View the data as a table
Easily edit the data using a variety of tools (Libreoffice, Gitea web UI, etc.)
Track and review changes
Manage access/permissions
Work in a distributed fashion
Additionally, it is easy to add automation to CSV files in Go or Python. While databases can be very useful for larger datasets, they are often overkill for a lot of things today, as most datasets (especially human-generated ones) now easily fit in memory. And when it comes time to use a database, it is easy to import your existing CSV data into a database.
“The way you get programmer productivity is not by increasing the lines of code per programmer per day. That doesn’t work. The way you get programmer productivity is by eliminating lines of code you have to write.The line of code that’s the fastest to write, that never breaks, that doesn’t need maintenance, is the line you never had to write.” – Apple WWDC '97 Steve Jobs Closing Keynote
How can we reduce the lines of code we need to write? Several ways come to mind:
Use OSS components
Build on someone else’s platform
Don’t implement “just-in-case” features
Removed unused code (linting tools can find this for you)
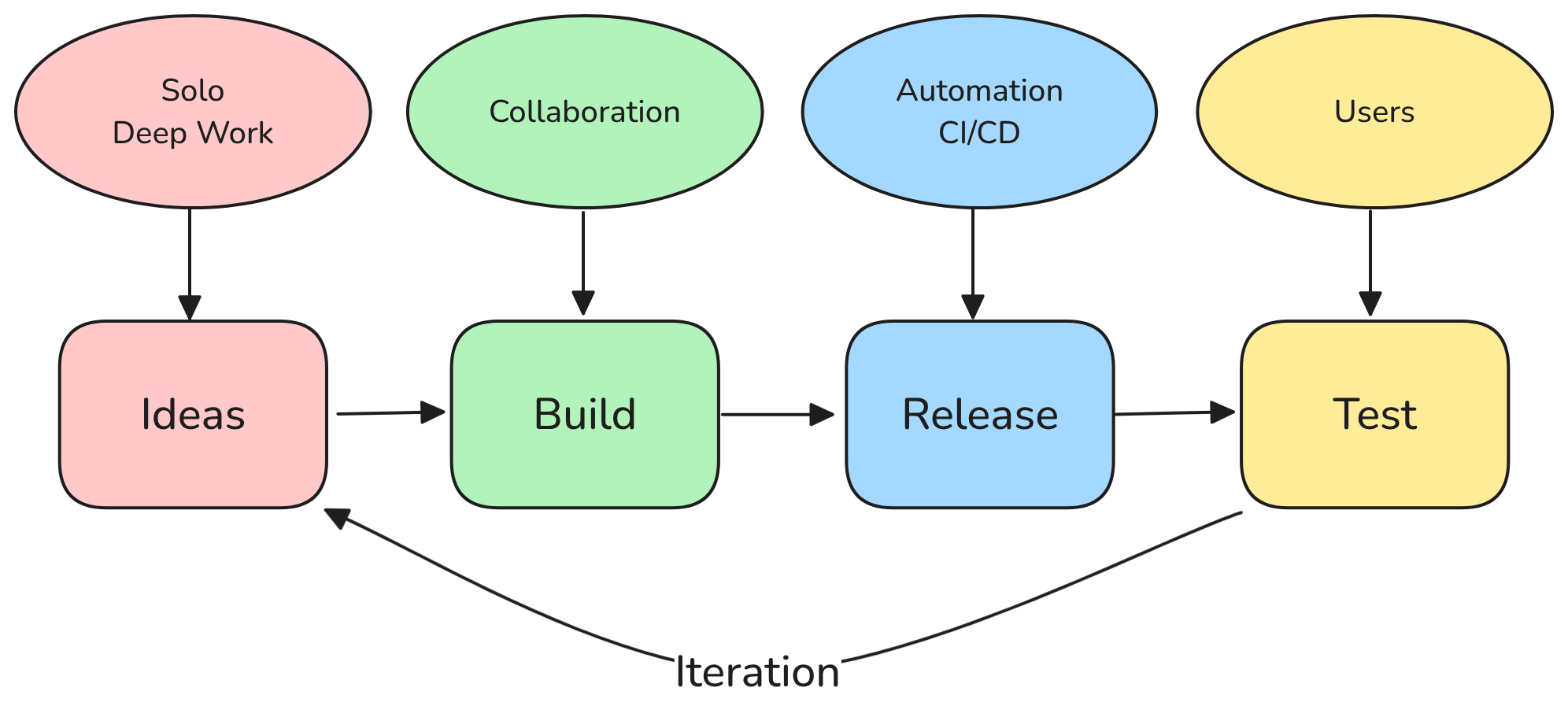
I’ve found it useful to define an iteration as a formal release (software that is packaged and users use, a PCB that you build, a prototype, a web app that you deploy, etc.). You don’t learn many things until you build and, more importantly, others use – even if your users are only internal. Practice formal releases during development, and then the process will be polished when you go into production.
To get really valuable feedback, we need users. If the product has not been released yet, find someone – external CI system, CEO, beta users, manufacturing people, accountants, your mom …
Often, when it leaves the developer’s computer, we find it does not even build, let alone run and do something useful!
While many great ideas and algorithms germinate in deep work and solo thinking, bringing a modern product (especially one containing software) to life require many iterations with feedback and learning. So lets propose a new release every week. But, the common objection is: we can’t do a quality release every week? A monthly release seems more reasonable, then we have plenty of time to get it right.
You can’t build a great product until you’ve built 52 bad ones.* If you only do an iteration every month, then you are looking at 4.3 years to get to good. If you do an iteration every week, then it only takes 1 year.
So instead of pining away about how can I possibly build a good iteration every week, quit worrying about building a perfect release, and instead focus on getting through the bad ones as quickly as possible.
* This may be an exaggeration, but if we are honest with ourselves, it is often astounding how many revisions it takes to get something working, let alone great.
Each phase is produced by someone or something. And the problems arise when we mix up who does what.
Great/innovative ideas usually don’t come out of a committee. Truth is a solo
pursuit. Evaluate ideas in meetings, but don’t try to come up with them there.
When a team is involved, collaboration is required. The better your collaboration culture/workflow, the more efficient your team will be.
Manually building, testing, and deploying software is a waste of human time – leave that to machines when possible.
Developers are horribly inept at testing/evaluating their own work. Any
outside viewpoint is useful – especially with user interfaces.
The faster you can do this loop, the faster you’ll learn, and the quicker you
can build something useful.
One thing I’ve noticed is when I release more frequently, I tend to automate. If releases only happen once every year, it is easy to neglect automation, CI/CD, etc. Automated tests are not needed as it is just quicker to manually test everything. But, with frequent releases, there is a subtle push toward scripting stuff, getting CI/CD running, etc. Instead of demanding more tests/automation, perhaps decide to release more often, and the automation will naturally follow.
Open a PR before doing the work, and explain what is going to be done.
In the end, you will go faster and do better work. Why? Because you are frontloading the tedious details that are difficult to find time for after the work is done.
This is the difference between the prototyping and product development mindset.
Most modern languages (Node.js, Python, Rust, Go, Zig, Elm, etc.) have their own package manager. So when should we update package dependencies? How about at the beginning of every PR cycle? I’m working on making this my standard practice when starting a new feature in an application – first, update all dependencies. There are several advantages to this flow:
Updating frequently means you are dealing with small changes.
Updating at the start of a dev cycle also gives you a standard time to do this. Otherwise, things like updating dependencies tend to get neglected.
Updating at the start of a dev cycle (vs end) gives you some time to exercise new modules during development before merging.
You automatically get security updates without having to track these too closely.
It feels right.
This also requires good tests, so that you can update with confidence. There might also be an issue with a team if multiple developers are updating dependencies at the same time. So in larger teams, perhaps one person or an automated process should do this. The key thing is that it does get done, and implement the needed automation to make this easy.
When designing a PCB, put down the smallest packages you are comfortable working with. Example: put down 0603’s instead of 0805’s, even if you don’t need the space right now.
Use a MCU with the most performance and RAM/Flash that is reasonable. Use a STM32 instead of a PIC16.
Everything else being pretty much equal, use Go instead of Python.
Why?
You may not need the space now, but the next iteration or variant of the product will likely be smaller, so why not plan for that now if it does not cost you anything?
Modern embedded systems that support field updates are flexible and can do a lot. New features will be requested. Plan for that now.
Python may be good enough now, but what happens when you need to add a handful more threads, more features, deploy to other architectures, and need higher performance?
Here’s the thing – it is impossible to predict all the directions a product will take. Set yourself up now to be able to reuse what you’re doing.
Today, we mostly think of iterating quickly on software, but it is becoming increasingly possible to also do this with hardware. A few ideas:
Printed circuit boards (PCBs) are now relatively cheap and quick to manufacture in low quantities from companies like JLCPCB (you can have a new PCB in less than a week at a very reasonable cost).
Companies like JLCPCB and Macrofab offer prototype assembly services.
You can now do more CI/CD type things with PCB design tools. KiCad has a powerful DRC rules engine and the ability to script a lot of operations (including generating outputs) from the command line. Run ERC/DRC in CI and generate outputs in CD. This allows you to make and deploy changes with a high level of confidence.
The above is YOUR Platform. Here’s the thing – the more complex and the higher value your product is, the more important it is to be able to iterate quickly and confidently on both hardware and software. As an example, Tesla updates the software in their cars frequently and continuously makes mechanical improvements (sometimes as many as 120-160 changes per week). If Tesla can do it with cars, you can probably do it with your low-volume industrial product.
Utilize a team chat tool such as Signal, Slack, Discourse chat, Discord, etc.. This does wonders for bonding teams (especially distributed teams). You can always mute it when doing deep work.
A lot of focus these days is on “good AI prompts.”
Some of the best prompts may be documentation and tests. Write your CHANGELOG.md entries first, then update the documentation, then write the tests, then tell the AI to update the code to match.
We tend to get it backwards—asking AI to generate tests and documentation after the code. Flip this and do the docs and tests first.
Your thinking will be better, and you’ll move faster.
 OSS can decrease or increase your code liability
OSS can decrease or increase your code liability