Fascinating talk about high availability/reliability:
 Next Cloud Outage - Pavel Nikolov, Section")
Notes:
- high availability and high reliablity
- no cloud provider can guarantee 100% uptime
- no a question of “if” but rather “when” your servers go down
- disaster recovery
- active/active (DNS switch)
- active/passive (spin up + DNS switch)
- periodic backup (manual recovery)
- no DR strategy (figure it out when it happens)
- RTO - Recovery time objective
- RPO - Recovery point objective (how much data can you afford to lose)
- what if there is a different approach
- self-healing
- cloud native
- no single point of failure
- expect that anything could go down at any time – even DNS
- BGP + Anycast IPs to the rescue
- IP packets
- Unicast - one-to-one
- Multicast - one-to-many
- Anycast - one-to-nearest
- many servers around the world with the same IP address, packet finds the nearest one
- Benefits from BGP (over DNS)
- DNS has TTL (usually at least 300s)
- BGP convergence takes seconds
- downsides
- you have to own an IP address range
- your cloud provider has to support BYO IP
- learning curve
- bird tool to announce IP addresses
- BGP is the backbone of the internet
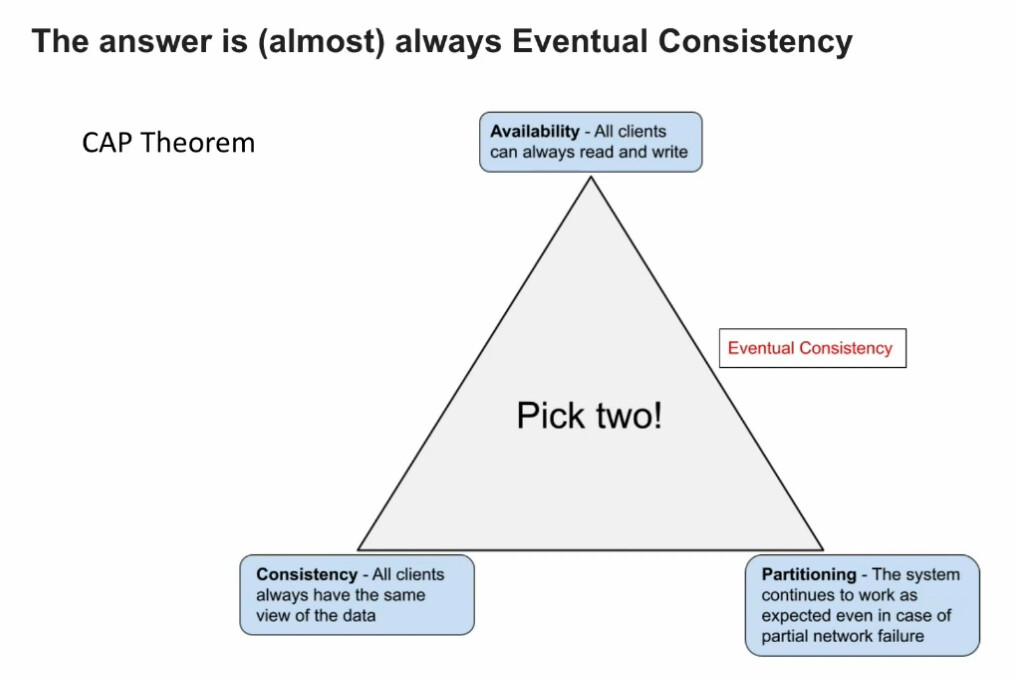
- What about data (consistency)?
- the answer is (almost) always Eventual Consistency
- most applications can tolerate eventualy consistetency
- most microservices do not need a database
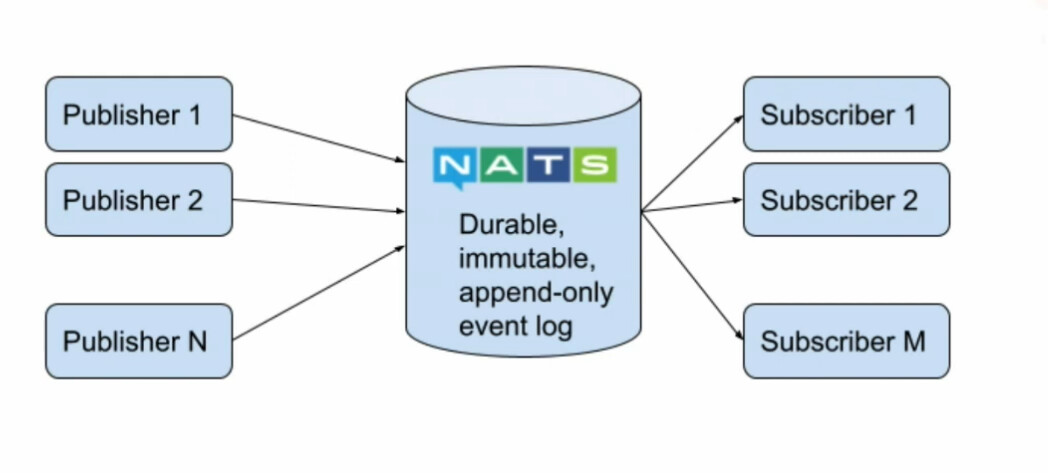
- Event sourcing is a perfect fit
- ideal for microservices architecture
- CQRS pattern - command query responsibility segregation
- producers don’t need to know about consumers
- consumers don’t know where events came from
- Requires a durable event store (NATS Jetstream or Kafka)
- Immutable data
- replay data since beginning of time
- Reproducible state
- Eventual consistency
@bminer, check this out.