Previously we defined our “customer” as someone who derives value from what we do. While it is useful to think of how the primary business value is flowing, hopefully we are providing value to our team as well as people outside our team. Some ideas:
Are Git commit messages helpful and easy to understand?
Are commits and PRs small enough to comprehend?
Is our work transparent?
Do we deliver what we said we would?
Is the code we write easy to follow and maintain?
Do we document what we are doing and why?
Do we share tests scripts and other automation that helps people use what we created?
There are two paths we can follow as a team or an organization:
what we do makes it easier for everyone else to do their job.
what we do makes it harder for everyone else to do their job.
#1 is the formula for scaling. #2 is the formula for stagnation and technical debt.
And which path a team or organization takes depends on culture. What are the expectations? Are they documented? And most importantly, what example do we set?
learn from mistakes and all the things that went wrong, and apply this knowledge to do better in the future.
assume because we’ve done something before the next time we do something similar it will “just work.”
If I’ve learned anything working in technology, things rarely “just work.” Nothing is easy.
Some can accomplish #1 because they have a great memory. For the rest of us, we need some process to capture what we have learned and a mechanism for applying this in the future.
Therefore, where there is scientific activity, there is a partial ignorance – the ignorance that exists as a precondition for scientific progress. And since ignorance is a precondition of progress, where there is the possibility of progress there is the possibility of error. This ignorance of what is not yet known is the permanent state of all science and a source of error even when all the internal norms of science have been fully respected.
Error may indeed arise from the present state of scientific ignorance or from willfulness or negligence. But it may also arise precisely from this third factor which we have called necessary fallibility in respect to particulars.
The encouragement of this inflated belief in the competence of the physician is of course reinforced by the practice of not keeping systematic and accessible records of medical error. Yet everyone knows that this is a false confidence.
Indeed, the only profession of which we know which fully and publicly documents predictive successes and failures is that of horse-racing correspondents in Great Britain.
The first reaction of physicians to the invitation to dispense with the masks of infallibility is likely to be a humane alarm at the insecurity which a frank acceptance of medical fallibility might engender in the patient. But we wonder whether the present situation, in which the expectations of patients are so very often disappointed during medical treatment, is not a worse source of insecurity.
As computer/software systems get more complex, are there parallels?
Your “customer” is someone who derives value and uses what you produce. Customers are both internal and external to your organization.
While it is good to focus on the flow of primary business value to the end-customer (that is what pays the bills), we can also think of everyone in the organization as being our customer. How can we provide value to everyone?
The best way to get to secure and reliable software is to fix the core issues.
If your programming language is not reasonably secure and reliable, adding more external tools to check and track down problems is helpful, but is likely not the most direct approach.
Likewise with architecture – getting the core architecture right is important. Adding external “watchers” and “fixers” to compensate for an architectural problem only complicates things, and complexity is the #1 enemy to both security and reliability.
In distributed computer systems, change is the constant.
Because a system can be networked, its capabilities are endless. The ability to connect to new and different systems means new systems (and value) can always be created, and things will change.
I once advised a young man – If you have some down time on a plane, in a hotel, etc., you might consider writing an essay or two about some of the issues facing you personally, or your organization. This is one of the best ways to think and discover truths. I’m often surprised and amazed what comes out.
Meetings would be much more effective if writing were part of the preparation (Amazon does this). But, alas, most think we can make progress by more discussion, meetings, emails, etc.
Truth is discovered, not invented. Truth cannot be forced. It is only when we approach the creative process with this humility that we can make progress. Designs devoid of truth are unwieldy, unreliable, hard to maintain, etc.
Modern, powerful tools like AI, CAD, computer languages, etc, may give us the illusion that great inventions start with us, but truly great designs/algorithms/processes are discovered, a simple reflection of truths that have existed for eternity. In the process of simplifying our designs, we often come closer to truth.
I wish I had understood the power of writing and the essence of truth earlier in my career.
Arch Linux does not have discrete releases – it is a rolling distribution where individual packages are continuously updated. Most people still raise an eyebrow at the mention of Arch Linux – how can that possibly work and be stable?
Having run Arch for many years, I can affirm it works very well. It is fast, efficient, and lets me run the latest software of everything with minimal fuss.
Today, a Linux distribution release is an artificial notion. A distribution’s main job is to deliver a collection of software to a computer. Each application has its own release cadence. Imposing a distribution release cadence on top of the package release cycle does not make sense.
But the distribution’s job is ensuring everything is stable and works together? Really? Does a distribution really test every one of the 1000’s of packages before every release?
If there is a serious problem in an application, it will be fixed soon in the main development branch. Requiring these fixes to be back-ported to an old release in a distribution is a lot of work. In some cases, it is nearly impossible to backport a change if things have changed significantly in the codebase.
A Linux distribution delivers the most value when each software package can be deployed to its users as soon as it is ready. Arch does this and then gets out of the way.
Different projects/products have different needs, but generally the trend in our industry is to release new software more often. There are several reasons for this:
Modern processors (even embedded microcontrollers) are very powerful and expandable, so it is possible to add additional features after the initial release.
Many devices are now connected, so updates can be deployed “over the air” automatically, rather than executing some manual operation.
Continuous Integration (CI) and other workflows are improving the quality of software such that we are more confident the software is always tested and working. Long manual testing/QA periods are no longer the best practice.
People are used to software updating on their phones/computers, so it is generally more accepted.
Connected systems bring security concerns which require updates.
Perhaps the main reason the release frequency is increasing is more cultural than anything. In previous times, software updates were perceived as “breaking things.” Especially in embedded systems, the mantra was: test it extensively, get it right, and lock things down. Updates are risky. However, the world has changed.
In the end, a software release means more value is being delivered to your users. And if our goal is to deliver value, then that includes releasing new software more often.
In the old’n days, a project was shipped and done, and we moved on to the next one.
However, with modern connected systems, we can deliver a lot of value after the initial release. Most of our engineering effort may be spent after the initial release maintaining and improving a product. How do we fund this? Some ideas:
Build the cost into the product up front (many consumer products use this model)
Pay for maintenance with new sales (be careful this is not a pyramid scheme)
Monthly/yearly subscription fees (might include a cloud service)
Fees for add-on features (high-end test equipment like oscilloscopes often use this model)
Pay for every update (hard to get customer buy-in)
The biggest mistake is not to plan for maintenance costs, or to surprise your customers with them. Be up front with the costs, but be more up front by communicating the value that you are continuously delivering.
This question really gets to the heart of our value to others. In everything we do, we need to think – am I delivering this work or information in a way that is easy for others to understand and use? Or do they need to do a bunch of unneeded/extra work?
Organizations composed of people who make less work for others scale.
Organizations composed of people who make more work for others collapse.
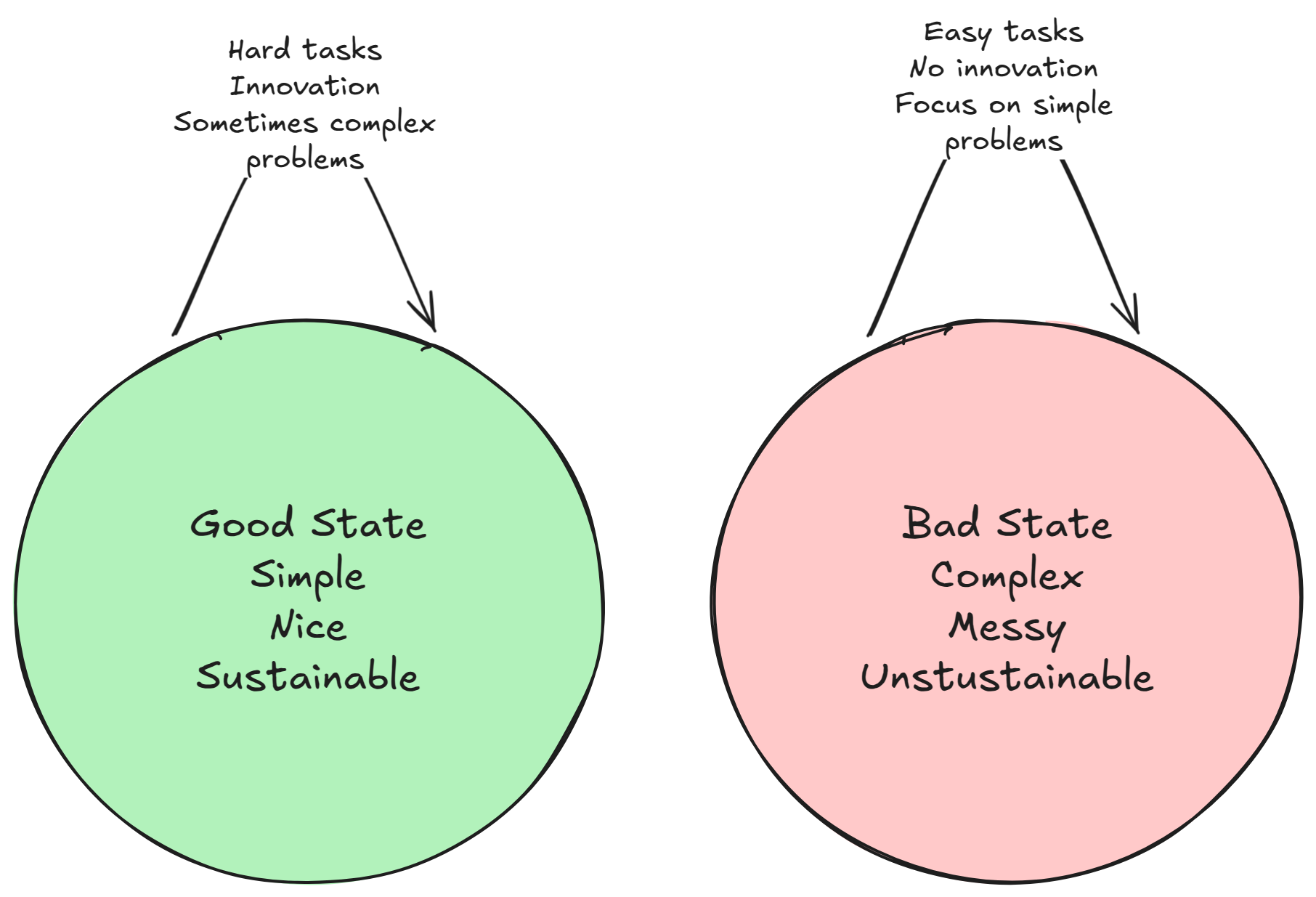
Improvement is not always easy, actually it is usually hard – really hard, and sometimes a complex path. But in the end, something likely got simpler for someone.
Getting to complex is easy and the natural state of things (chaos).
The path and the resulting state are two different things.
We can do the hard/complex things and get to a simple/nice/sustainable state.
Or we can only do the the easy things which results in a complex/messy/unsustainable state.
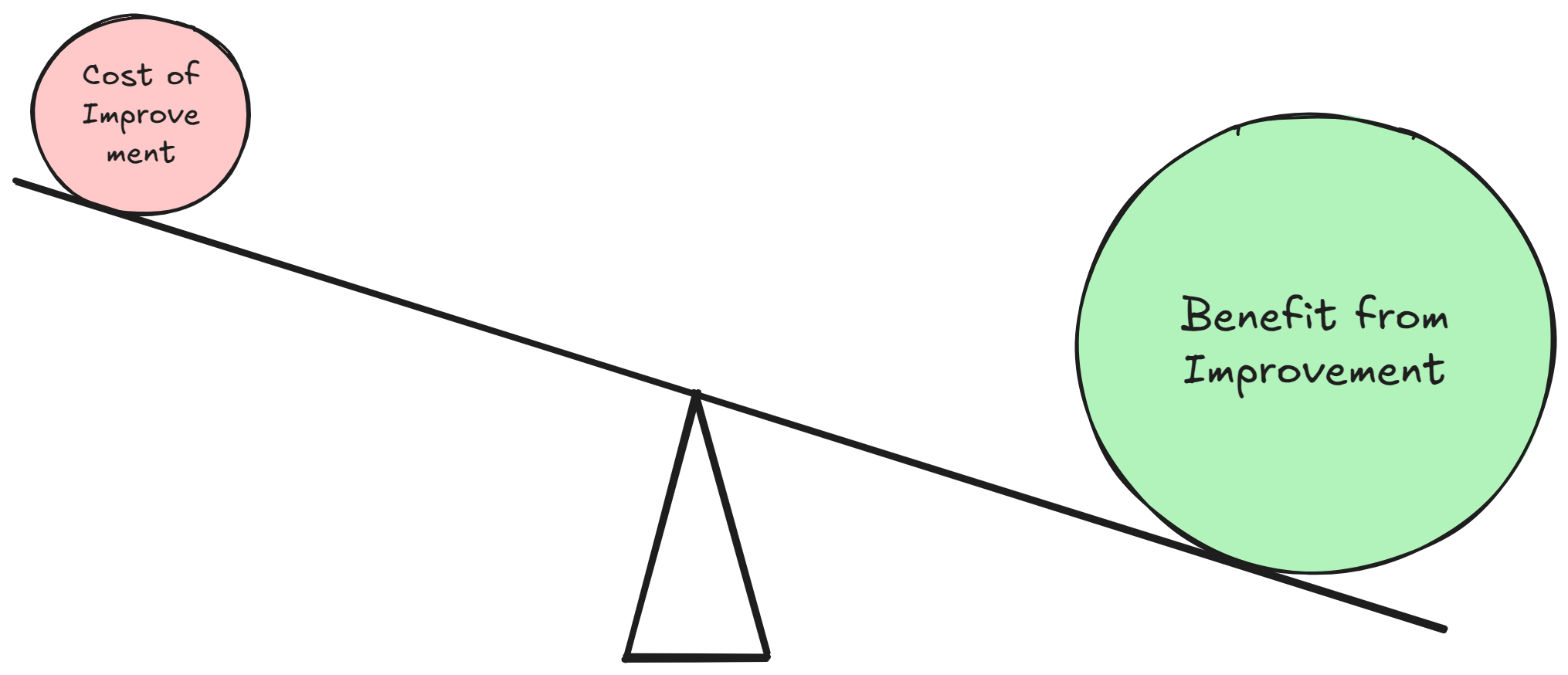
As discussed previously, improvement is sometimes hard – really hard. So how do we justify it?
The payback comes when we improve something once, and then something else gets lots easier many times.
An example might be automating a release process. If it takes 1 hour to manually do a release, and it takes 6 hours to automate it, then in 6 releases we break even and releases after that is gain.
We want the balance to tip heavily toward the gains from repeatedly using the improvement, not the effort spent implementing improvements.
For this to work out, we need a way to leverage improvements in the future. We need tools, workflows, automation, and processes to capture improvements – YOUR Platform.
For everyone downstream of us who uses or is influenced by what we create or do, things should be simpler/better/easier – because we did something. This is the formula for creating wealth.
The alternative is that we produce no value for others. It would be easier for someone to do whatever we’re doing themselves, or in extreme cases what we are doing should not be done at all. This is the formula for debt.
Whenever debt creation is greater than wealth creation for too long, the family/organization/company/country we’re a part of collapses.
Wealth can include more than money – good will, positive energy, intellectual property, spiritual well-being, relationships, community, health, etc.
In whatever sphere we’re a part of, do we create wealth or debt?
I’m currently reading The Checklist Manifesto by Atul Gawande. Gawande is a surgeon who wants to find a way to reduce the mistakes and their catastrophic consequences during surgery. So he investigates other industries such as air travel and the construction of large buildings. What he finds is the checklist is at the center of their processes. (more on this later …)
With software, our failures (with some exceptions) are usually not as catastrophic as people dying in surgery, airplanes falling out of the sky, and large buildings collapsing. Another difference with software is that is easy and cheap to fix by deploying an update (hence the prefix “soft”). People, airplanes, and buildings are not this way.
Thus we can get sloppy. Motivation to “get it right” can wane as pressure to ship increases and we can “always fix it later.” The problem is that this approach encourages accumulating technical debt. Technical debt will just as surely crush the soul of a programmer and eventually the company, just not in dramatic news-catching ways.
Building a sustainable technology company requires an extreme level of discipline because there is no external force requiring you to do it right. For many technology industries, there is not any regulatory agency watching over them – it is entirely up to YOU, and that is where YOUR Platform comes in.